Performance Record of Raspberry Pi 4B (CPU, Disk, FFMPEG, CV, llama2)
This blog is used to record some reviews of Raspberry Pi 4B.
Temperature
Fans and Large Fans are:

Why use a large fan?
Because a small fan on the case can cause noise from airflow through the case grid, which is not pleasant but not very loud. A large fan does not have this problem and it also uses the Raspberry Pi’s USB port for power supply.Additionally, because the Raspberry Pi is located next to the large hard drive, it can also cool the system.
Idle
| Temperature(℃) | |
|---|---|
| No fin + No fan | 41.3 |
| Fin | 38.9 |
| Fin + Fan | 36.5 |
| Fin + Large fan | 29.7 |
Full Load
| Temperature(℃) | |
|---|---|
| Fin | 69.6 |
| Fin + Fan | 56.9 |
| Fin + Large fan | 50.6 |
I/O speed
Raspberry Pi 4B Micro SD has a write speed of 45 MB/s, but occasionally it can run up to 100 MB/s for reading, which is mostly similar to the read speed (Jeff tested that Raspberry Pi 5 can run full 100MB/s).
CPU performance
Below I write programs using Clang and ISPC (parallel computing) to test some performance of the CPU. Considering the impact of write speed of Micro SD Card, only test non-stored programs here.
4096x4096 Float64 matrix calculation
If divided 4 blocks for parallel computation:
| Device | Serial | Parallel |
|---|---|---|
| Raspberry Pi 4B (4C4T) | 66.12s | 51.72s |
| (reference) Mac mini 2018 i5 (6C6T) | 17.76s | 6.08s |
The process occupies approximately 192.8 MB memory. It can be seen that the improvement brought by the use of parallel computing and segmentation tasks, but Raspberry Pi 4B is not nearly four times as expected.
I think the blocks processed each time exceed the size of each core’s 32kB data L1 cache. Using a smaller block maybe better? In theory, it is the fastest on 16x16, which is divided into 256 blocks, because the maximum matrix stored in 32Kb is about 22x22.
Each of the tests uses the same matrix:
| Blocks (each block size) | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| 4 (1024x1024) | 40s | 39s | 47s | 41s |
| 8 (512x512) | 56s | 47s | 55s | 48s |
| 16 (256x256) | 37s | 39s | 40s | 46s |
| 32 (128x128) | 38s | 49s | 48s | 50s |
| 64 (64x64) | 45s | 49s | 45s | 42s |
| 128 (32x32) | 41s | 37s | 43s | 40s |
| 256 (16x16) | 38s | 38s | 43s | 37s |
16x16 maybe not fastest every time, but you can see 16x16 is definitely the first tier. We choose 40s as result, it reaches 1.653 times of serial, which is close to twice times.
Optimized matrix multiplication (measuring floating-point performance)
Use optimized matrices and algorithms and task. This test can achieve 70% to 90% of peak floating-point performance, but the actual situation still depends on the operating status, system, and other configurations.
| Device | Floating Point Performance (GFLOPS) |
|---|---|
| Raspberry Pi 4B | 11.91 |
| (reference) Mac mini 2018 i5 | 200.03 |
The comparison group here achieved 70% of the theoretical performance (200/288), and the Raspberry Pi was much higher than the floating-point value obtained from the previous test.
Sort
| Devices | Parallel Computing + Tasks |
|---|---|
| Raspberry Pi 4B (4C4T) | 2.45x |
| (reference) Mac mini 2018 i5 (6C6T) | 5.86x |
The process occupies approximately 192.8 MB of memory. It also doesn’t achieve the 4 times expected result, also is about 2 times.
Mandelbrot
| Devices | Parallel Computing + Tasks |
|---|---|
| Raspberry Pi 4B (4C4T) | 8.58x |
| (reference) Mac mini 2018 i5 (6C6T) | 44.03x |
| (reference) Intel E5-2690 v4 x2 (28C58T) | 130.18x |
You can see the improvement of each device has reached twice the number of threads.
Some my opinions
These test proved that the low cache of BCM2711 (32kB of data + 48kB of instruction L1 cache per core and totally 1MB L2 cache) results the required data for computation is slightly larger, the parallel performance will not reach the expected, and cannot fully utilize the performance of all cores.
Of course, I suspect this is also related to the lack of optimization and improvement of the new system (Bookworm). Let’s see if it will be better in the future.
FFMPEG
Sometimes need to convert formats, transcoding and fixing issues with some videos. I prefer to use ffmpeg.
The unit ‘x’ in the test results meaning the ratio of the frames processed per second and the average frames in the video, like’123x’. For example, if the video is 24 Hz, processe 48 frames per second, it will display ‘2x’; If only 12 frames per second, ‘0.5x’ will be displayed.
Test Video: 950MB FLV Tiktok live record with 500K bitrate.
Convert Video Format
The fastest way to convert formats is to directly copy the stream, as follows:
$ ffmpeg -i input.mkv -c copy out.mp4
This method does not modify any audio/video, encoder or bitrate, because it directly captures the stream into a new format (notice the selection of subtitles and audio tracks).
The results and comparison of Raspberry Pi 4 are as follows:
| Device | Speed |
|---|---|
| Raspberry Pi+Micro SD (45MB/s) | 35x |
| Raspberry Pi+USB NVMe SSD (approximately 350MB/s) | 617x |
| (reference) Mac mini 2018 i5 (read 2400 write 1200) | 2410x |
As the speed of the hard drive increases, the speed of transcode increases.
Notice the speed of the USB SSD mentioned above is limited by the solid-state drive itself, as it uses BG4 and does not have memory as a buffer. Due to the addition of single flash memory particles and TLC NAND, it is not only can’t achieve expected IOPS performance when using USB external connections (internal connections use system memory as a buffer), but also inferior to other SSDs with memory buffering or multiple NAND.
IOPS is the number of operations of read and write per second, which affects the system’s response speed.
Transcode
The simplest commands in daily life:
$ffmpeg -i in.flv out.mp4
| Device | Speed |
|---|---|
| Raspberry Pi + Micro SD (45MB/s) | 0.23x |
| Raspberry Pi + USB NVMe SSD (approximately 350MB/s) | 0.452x |
| (reference) Mac mini 2018 i5 (read 2400 write 1200) | 2.7x |
Hardware accelerated transcoding
To use hardware accelerated transcoding on raspberry pi, the command like:
ffmpeg -i in.flv -c:v h264_V4l2m2m -b:v 1500k out.mp4
The 1500k is not the bitrate of the video. It is the bitrate of the automatic transcoding in the previous section. I will use it to compare. I also tested other bitrates and the speed is similar like below:
| Device | Speed |
|---|---|
| Raspberry Pi + Micro SD (45MB/s) | 2.1x |
| Raspberry Pi + USB NVMe SSD (approximately 350MB/s) | 2.36x |
| (reference) Mac mini 2018 i5 UHD 630 (read 2400 write 1200) | 4.36x |
Raspberry Pi 4B has increased its speed by 6-10 times after using hardware acceleration. However, the ‘h264’_V4l2m2m` occupies CPU usage. And if you are running other programs, the performance will decrease slightly.
Machine Learning
The speed of image recognition and large language model was tested.
Image Identification
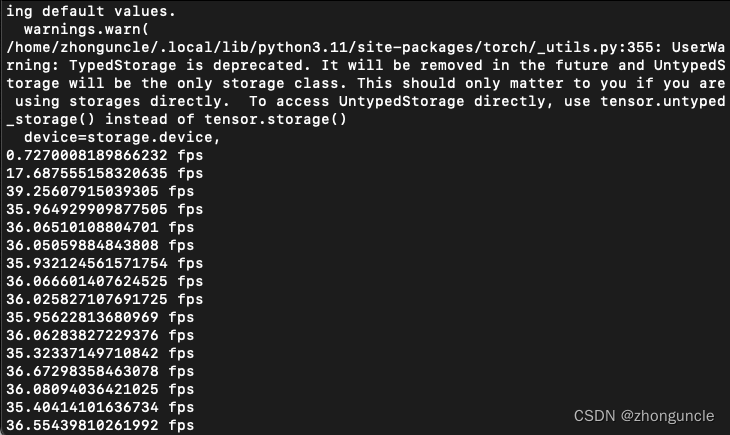
30 frames 224x224 size from the camera, using mobilenet_v2 for recognition, the speed is about 36 fps.
Large language model
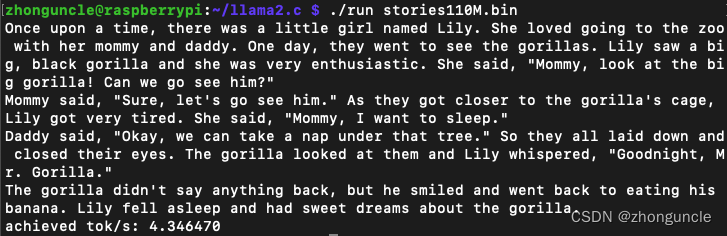
Use a small large language model karpathy/llama2.c for testing. Models with different size parameters have different speeds:
| Model parameter size | Speed (tokens/s) |
|---|---|
| 15M | 30.1 |
| 42M | 11.2 |
| 110M | 4.3 |
Why I still buy Raspberry Pi 4
Why although Raspberry Pi 5 has been released, I still bought Raspberry Pi 4B, considering the following points:
- The power consumption of Raspberry Pi 5 has increased by 10 Watts, and doesn’t need to buy a special chargers (4B can many current phone chargers use directly, even can use the USB charger port on monitor). It also needs a heat sink and fan (Jeff’s test results have proven this).
- Although the performance of Raspberry Pi 5 has increased by 2-3 times, the actual price has also increased much. You may say that the official price has only increase $5. However, it needs to be considered that there are not many 5V5A chargers currently used, and a heat sink must be used. So based on the price from the official designated merchant, 4GB is ¥550(about $80), plus the official charger and heat sink, that’s 700 yuan (about $100), and at this price, I can buy an N100 miniPC with twice the performance and M.2 + SATA interface.
- I need to use it to debug Raspberry Pi Pico, which happens to have a debugging interface on Raspberry Pi, and it doesn’t require any performance.
- Raspberry Pi 5 may have some issues because it just comes out. I want to use it for a long time. Now Raspberry Pi 4B has sold at least 3 million, the possibility of serious problems is impossible.
- To be honest, last time I bought a Raspberry Pi 4B, I didn’t use it’s performance fully. And Raspberry Pi 5 has not publicly stated that it does not support OpenCL, and 4B cannot be used.
- The most crucial thing is that the Raspberry Pi 5 has not yet started selling in China, and the Double Eleven subsidy Raspberry Pi 4B 4GB bare board only costs 330 yuan($48).
I hope these will help someone in need~