Why hard drive lost much performance via USB?
In hard disk performance, IOPS is a very important parameter. In terms of speed, this is the most important parameter to pay attention to, rather than the sequential read and write performance or random read and write performance that many people measure.
This is because whether it is sequential read and write or random read and write, it is actually the disk unit size multiplied by the read and write rate, and the unit of this read and write rate is generally IOPS (I/O operations per second). **In other words, both random read and write performance and sequential read and write capabilities are reflected in IOPS, and random read and write IOPS is the “upper limit” of IOPS. **
Disk unit sizes are now typically at least 4 KiB, or 4096 bytes, up from 1024 bytes on early computers, also known as a block. Specifically, when a file is transferred, even a complete file, such as a movie in MP4 format, is transferred piece by piece according to the disk unit content.
It should be noted here that the generally referred to as “random performance” is not the read and write performance of small files as the saying goes, but the read and write performance of files with a size of 4096 bytes. Therefore, high-performance hard disk parameters generally list their own random read and write IOPS data as “4K random performance”, and even include test methods and ranges. However, consumer-grade hard drive parameters are generally simply written as “random performance”. For example, the following figure shows the performance parameters of a typical WD Blue SN550 NVMe PCIe M.2 1TB:
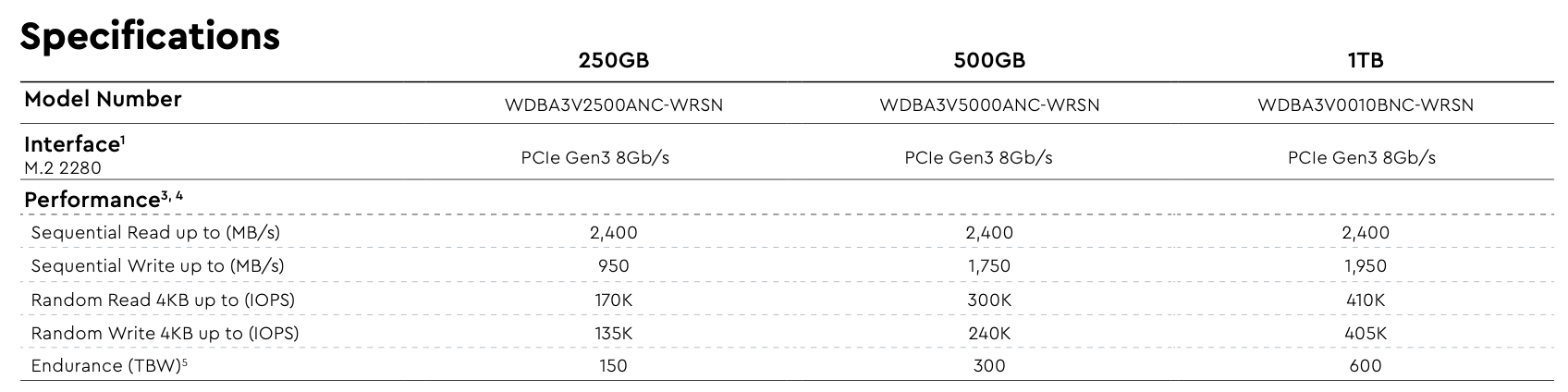
You can see that the random write is 405,000 IOPS, then multiply 405000 by 4 KiB to get the theoretical random write performance, which is approximately 1620000 KiB/s, which is 1582 MiB/s. If you look at the random write speed of the SN 550 1TB, you will find that the peak random write speed is around this value.
At this time you may be curious and say:
- Then why do I often see some tests saying that random read and write are only a few hundred or even tens of MiB/s?
- Why do the “4K performance” queue numbers in some test software range from hundreds to thousands, but when the queue number is 1, it only amounts to dozens?
Before answering these two questions, you need to understand how the system reads or writes to the hard disk, and the concept of threads in the system (you may be surprised that threads are not a concept on the CPU, but this is a mistake, One-sided concepts need to be corrected, which will be discussed in detail later).
How the system reads and writes
The program reads and writes to the hard disk through the system level. In UNIX-like systems, this part is performed by the two classic system calls write and read. The system will find or write the information content according to the address of the block where the information is located plus the offset, and the size of this block is generally 4096 bytes.
For example, if you need to find a file that is exactly 4096 bytes in size, then you only need to find this block or locate this block (this is why current systems have “4K alignment”, if not aligned, the speed will As described in the next paragraph, it is much slower. In addition, the hard disk capacity is now very large, which magnifies the effect of performance degradation).
Sequential reading: When you finish reading the current block and need the next block, the address happens to be the next block, which saves time. Therefore, after passing an “inflection point” in size, both reading and writing speeds will increase. If there is no improvement, it will hit the “top” of IOPS. But if you want to find or write a file smaller than 4096 bytes, then you have to add the offset. So you will find that once there are many files smaller than 4096 bytes, even sequential reading and writing will be extremely slow, which is much larger than the difference between large files and 4 KiB. Taking writing speed as an example, the latter can be slowed down by 80%, but the former can even be slowed down by 97.3%.
Random read and write speed generally refers to the rate at which a block in the hard disk can be randomly read or written per second. This actually simulates daily use, because in daily use, the locations of many files and programs are not continuous. However, the random read and write performance marked by many hard disks is not 100% hard disk span, that is, each block is divided inside the hard disk (for example, according to the flash memory chip), which is equivalent to the block address and offset. one extra. For example, if a solid-state drive has 4 flash memory particles, file A is on particle 1, and file B is on particle 4, then it may take some time to read file A and then read B, so the IOPS is not what is in the parameter table. .
Here we take the P4800X, which is currently the second strongest random read and write, as an example (no test data can be found for P5800X). The following figure is its parameter table. The random read and write performance uses 100% hard disk span:

Why the number of queues affects random read or random write speed
Here you need to know what a thread is: a thread is the unit of resource allocation by the system, including a series of resources such as CPU usage time, memory, address, network (note that it is not divided equally), and the process is the status of the program.
**It needs to be emphasized here: the multi-threaded programming model has been widely used long before the emergence of multi-core processors (I know the earliest example is in the 1980s). It is not that multi-threaded programming started with the CPU having multi-threading technology. , but with multi-threaded programming technology, only multi-threaded processors are available. **
Why is there a multi-threaded programming model? In the early days, one process used one thread, but a problem would arise at this time: assuming that this program needs to compare the contents of two text files, then this program needs to first read a character of A, and then read a character of B. Then compare the two characters and do this step again. When fetching characters, the computing unit is idle. So if you add a thread to this process, then this process can perform another task while calculating or reading. This saves some running time and improves performance on one processing core.
An explanation needs to be made here: after reading the above paragraph, you may think that it is waiting for the computing unit or other units. In fact, this is not the case. It is waiting for the execution context (execution context) to be available. The execution space is usually Cache or register.
The multi-threading technology of the CPU is not a “one set of computing unit, two sets of space” structure like “B runs while A is waiting” as mentioned in the popular science video. Instead, there are two sets of computing units inside the CPU core but only A structure of Cache and register execution context for computing unit operations. The internals of a single core of a multi-threaded CPU are as follows:
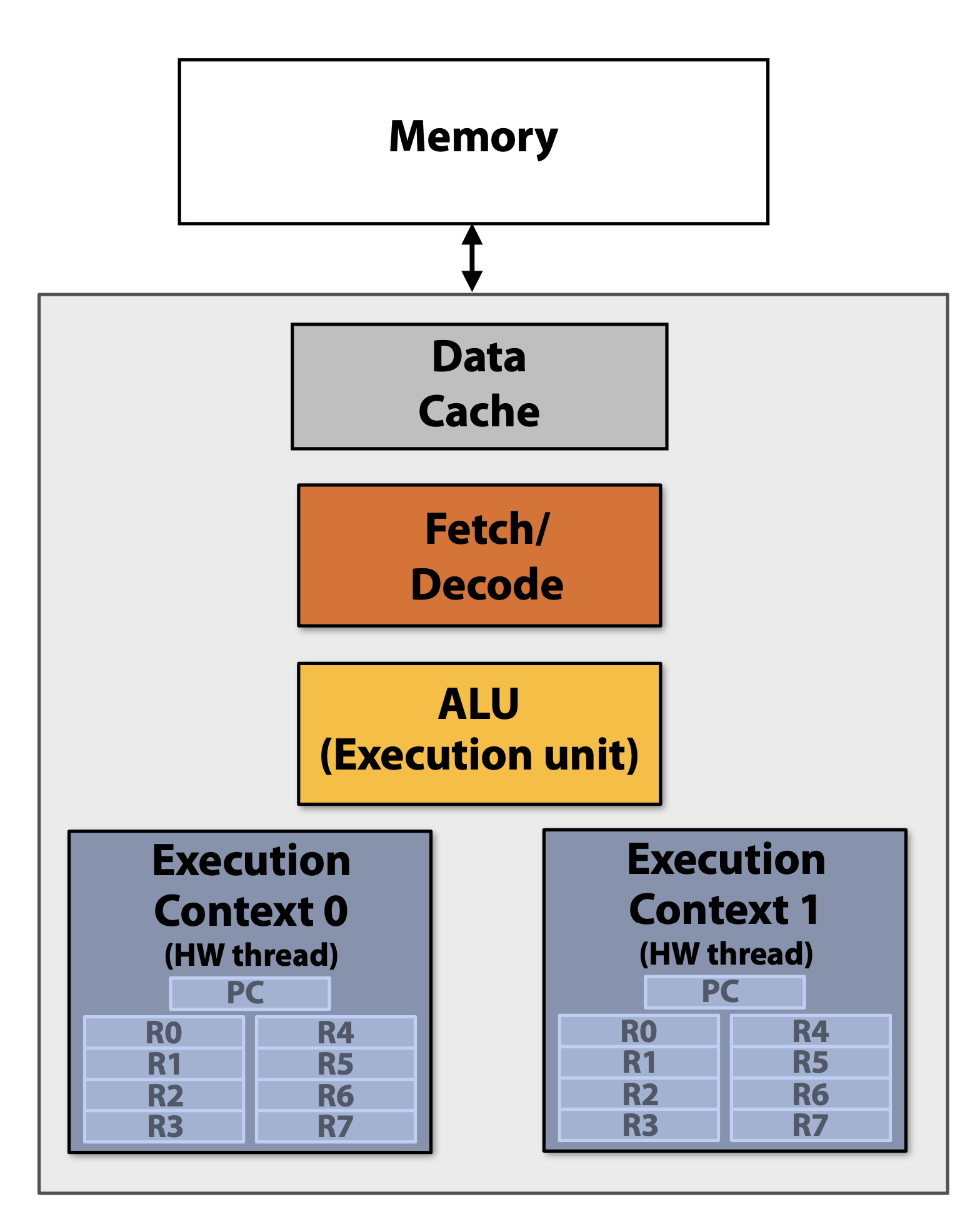
In addition, the description “B runs while A waits” seems that the CPU is only for “parallelism” of multiple programs, but this design is mainly for “parallelism” within a single process in the computer field. You can look at the information of a certain process in Activity Monitor (Mac) or Resource Manager (Win). Nowadays, a process generally has several or even a dozen threads. For example, the following is a screenshot of the more commonly used QQ. You can see There are 60 threads:

Therefore, the multi-threading technology of the CPU is not implemented by software, but by hardware. This mechanism is to cater to the original “multi-threaded programming model”.
As mentioned before: the program reads and writes files through the system layer. Even on a single-core processor, multi-thread programming will bring performance improvements. Computer resources include not only CPU time and memory space, but also storage devices. Of course, this part is system-wide and cannot be directly accessed by programs. But the principles are the same: multiple queues are equivalent to multiple threads, which can improve the utilization of storage devices and try their best to perform read operations, so that they can approach the theoretical read and write performance. When there is only one queue, the CPU may be busy, or the transmission channel may be “blocked”, which may cause the storage device to enter limits and cause the transmission rate to drop. At this time, the queue can be added to reduce the idle time of the hard disk and improve utilization.
Why does the hard disk cause a lot of performance loss when connected via USB?
Generally speaking, the CPU itself does not support USB controllers, so it connects a USB controller and then expands the USB interface. The PCIe interface is supported by the CPU itself and can communicate directly with the CPU, plus general The USB controller is not directly expanded through the CPU, but through the PCH, which requires an additional layer of transmission and conversion.
In addition, the commonly used SATA interface, even if it is built-in, requires a SATA controller for communication, while NVMe can directly use PCIe for communication.
This leads to the high latency when using a USB external hard drive. On the other hand, the USB controller prevents NVMe from directly connecting to the CPU. In the end, the IOPS of the hard drive will be reduced a lot, and lags will occur. Pause and slow down. The USB of some laptops or devices is even extended through expansion boards or other lines, which results in even more drops. **It should be noted that these behaviors have little impact on the speed of sequential reading and writing due to their impact on IOPS. However, they have a great impact on the speed of random reading and writing and daily use. Problems such as software lags are likely to be due to this. **
For example, the following is a comparison between the built-in Toshiba BG4 512GB and the 10 Gbps USB external Western Digital SN550 1TB (10 Gbps on the expansion board and 5 Gbps on the motherboard). According to the parameters, the SN550 will be stronger than the BG4, and the 10 Gbps one will also be stronger than the 5 Gbps, so here will show how much impact the computer’s internal circuit design will have on performance:
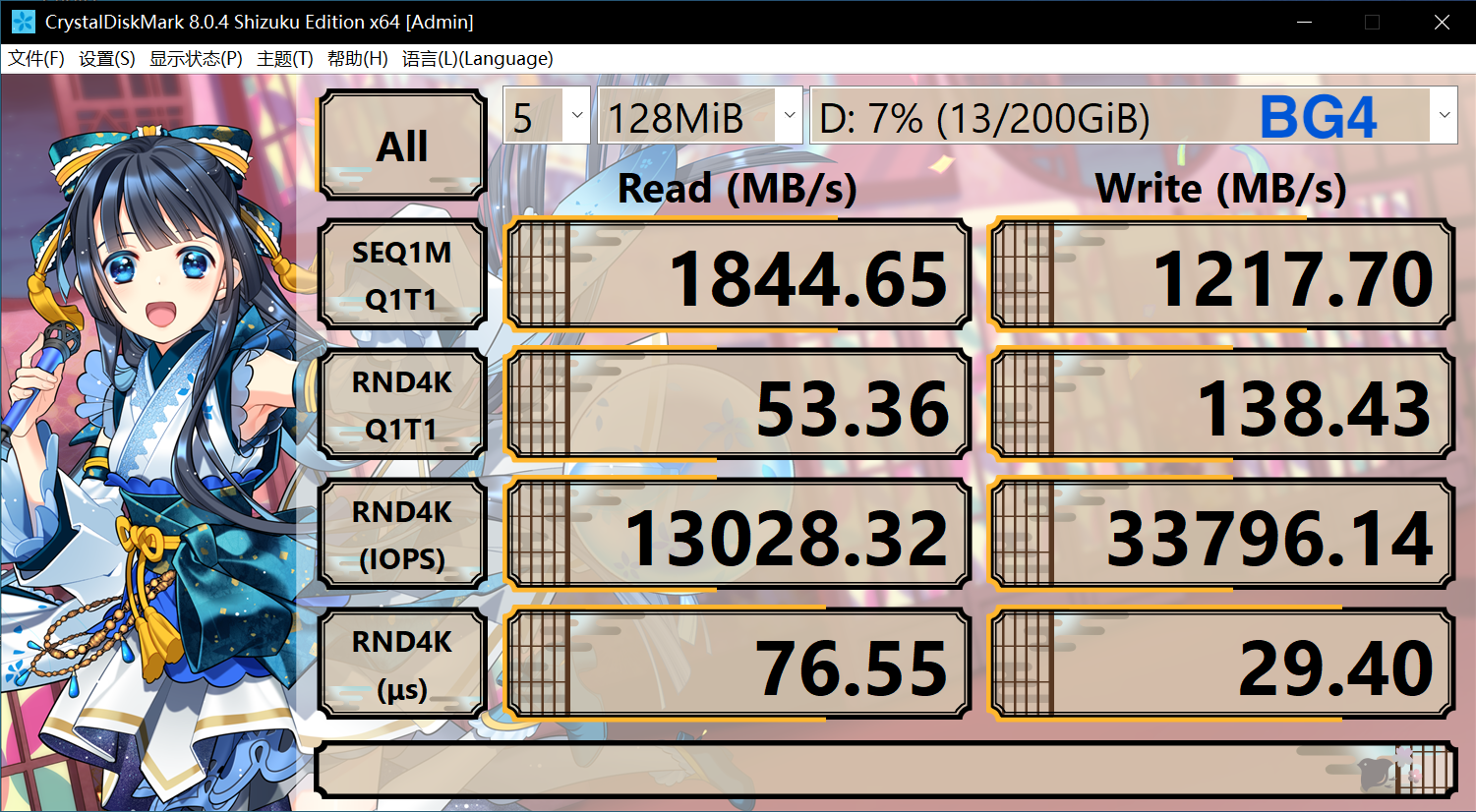
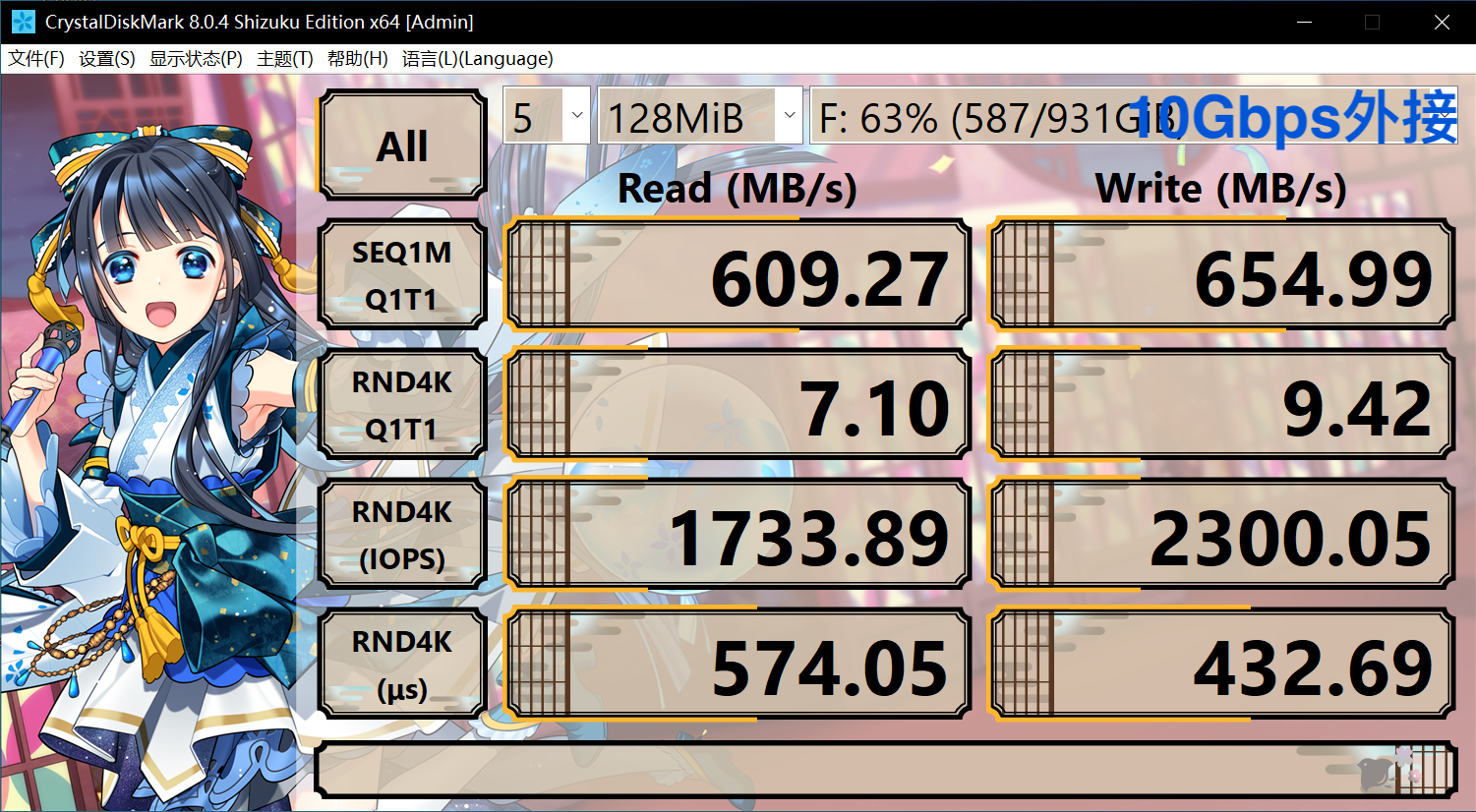
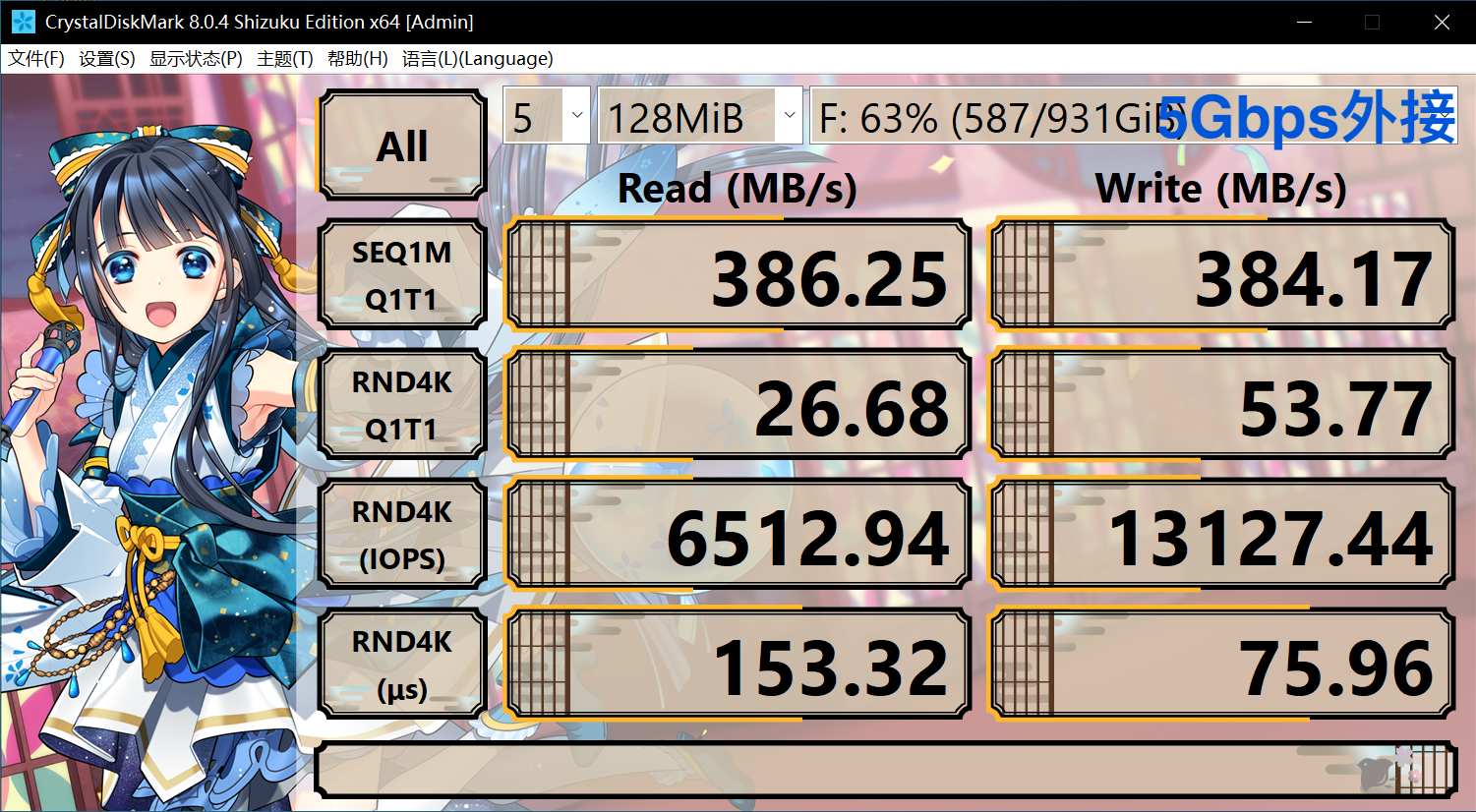
It can be seen that although the theoretical performance of BG4 is much weaker in all aspects, since SN550 requires multi-layer conversion to connect to USB, it will be found that the 4K random read and write speed is much lower than the built-in (calculate and you will find that the 4K random read and write speed is Without hitting the interface peak rate or the hard disk sequential read and write speed), in this case, the external hard disk will experience lags and serious performance problems in hard disk-intensive software like Thunder. In terms of sequential reading and writing, due to some line problems, the performance is less than 10Gbps or 5Gbps.
In addition, it can be found that although USB external connections are also used, the USB peak rate on the motherboard is much slower, and both usage and random read and write capabilities are much better than the 10 Gbps USB on the expansion board. Although this is still much slower than a built-in PCIe hard drive, and there will still be lags in some hard drive-intensive software, it is much better than the one on the external board. However, due to the fast sequential reading speed, it is relatively fast to copy large files in batches. However, if other operations are performed at this time, it will be stuck. This is because the hard disk delay will be very high. You can check the hard disk in the resource manager. The response time is often as high as hundreds of milliseconds or even thousands, that is, an operation has to wait for about one second, while the built-in is unlikely to have such a response time in this case.
I hope these will help someone in need~