Simple NN test implemented in Pytorch on laptop and Mac mini 2018
I tested the current laptop and Mac mini running 10 iterations of the simplest single-layer NN (with backpropagation) built using Pytorch, so that I will know what parameters to pay attention to when purchasing equipment in the future, but unfortunately not.
The first is the performance of each device:
| Dell Inspiron 7490 | Mac mini 2018 | |
|---|---|---|
| CPU | i7 10510U 4C8T 2.30-4.90GHz | i5 8500B 6C6T 3.00-4.10GHz |
| Cache | 8MB | 9MB |
| Memory | 16GB DDR3 2133MHz | 32GB DDR4 2666MHz |
| Best GPU | MX250 4SM 384 CUDA Core 64-bit 2GB GDDR5 | Intel® UHD Graphics 630 1.10 GHz |
The following results are the best or middle values (if float range is large). The only pity is that the iMac 5K was sold early, otherwise I can test the MPS acceleration results. Because Python’s MPS acceleration is only supported devices on Apple chips or equipped with AMD graphics cards.
| Dell Inspiron 7490 CPU | Dell Inspiron 7490 GPU | Mac mini 2018 |
|---|---|---|
| 123.15s | 107.79s | 87.94s |
The most amazing thing is 8500B actually takes less time than the MX250 CUDA acceleration. Of course, it is high probability due to system. After all, Windows performance is indeed not very good.
In addition, memory bandwidth is really important (although size is also important). The bandwidth of MX250 is too small. The 64-bit GDDR5 bandwidth is 48GB/s. After increasing iteration and reducing learning speed, the CUDA calculation rate isn’t go up. The memory bandwidth of general consumer-grade graphics cards is sufficient, but the MX250 is positioned as a thin and light notebook.
This reminds me of the test I watched from other Running PyTorch on the M1 GPU, one of the data is RTX 3080 Laptop Slightly slower than RTX 2080Ti:
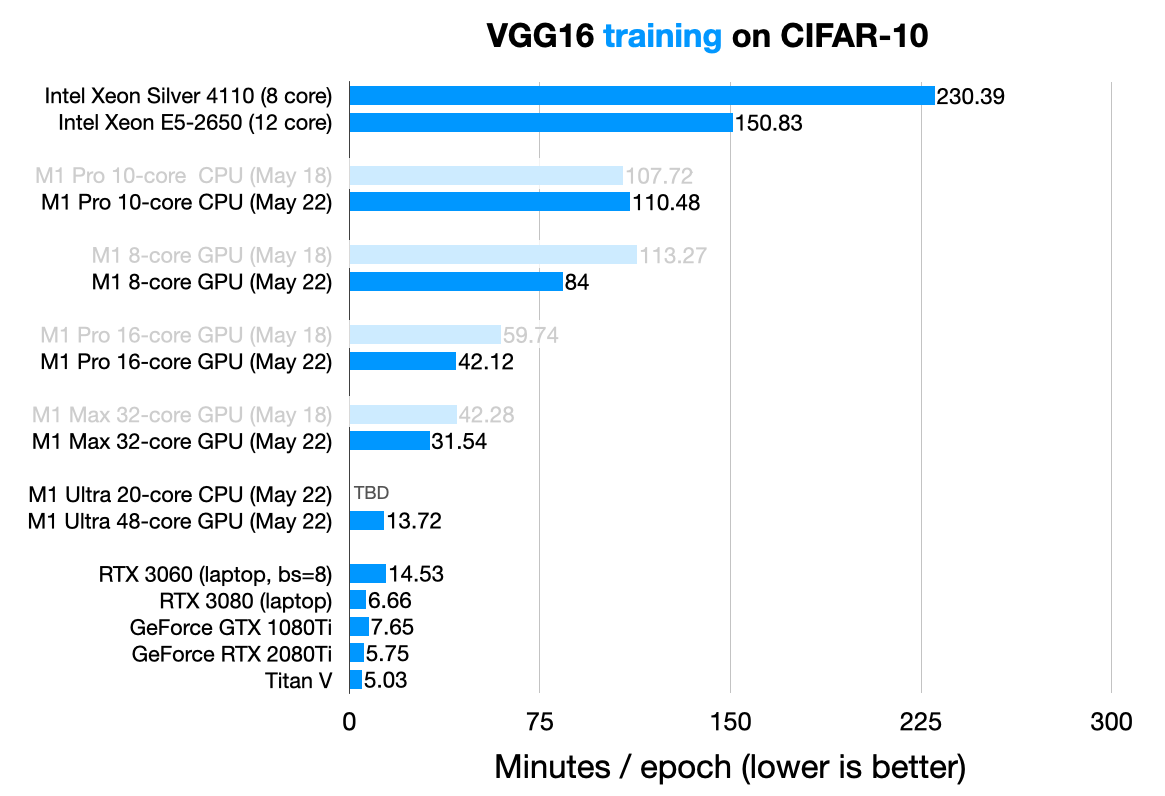
The specs and results of each graphics card in the above picture are as follows:
| GTX 1080Ti | Titan V | RTX 2080Ti | RTX 3060 Laptop | RTX 3080 Laptop | |
|---|---|---|---|---|---|
| Cuda Cores | 3584 | 5120 | 4352 | 3840 | 6144 |
| Graphic memory interface | 352-bit | 3072-bit | 352-bit | 192-bit | 256-bit |
| Graphic memory rate (Gbps) | 11 | 1.7 | 14 | 14 | 14 |
| Graphic memory bandwidth (GB/s) | 484 | 652.8 | 616 | 336 | 448 |
| minutes/epoch | 7.65 | 5.03 | 5.75 | 14.53 | 6.66 |
Because all GPU’s graphic memory is about 10 GiB, so I ignore it.

It may not shows something, so I only keep “Cuda Cores”, “Graphic Memory Bandwidth” and “Performance”. Because other parts are related to “Graphic Memory Bandwidth”:
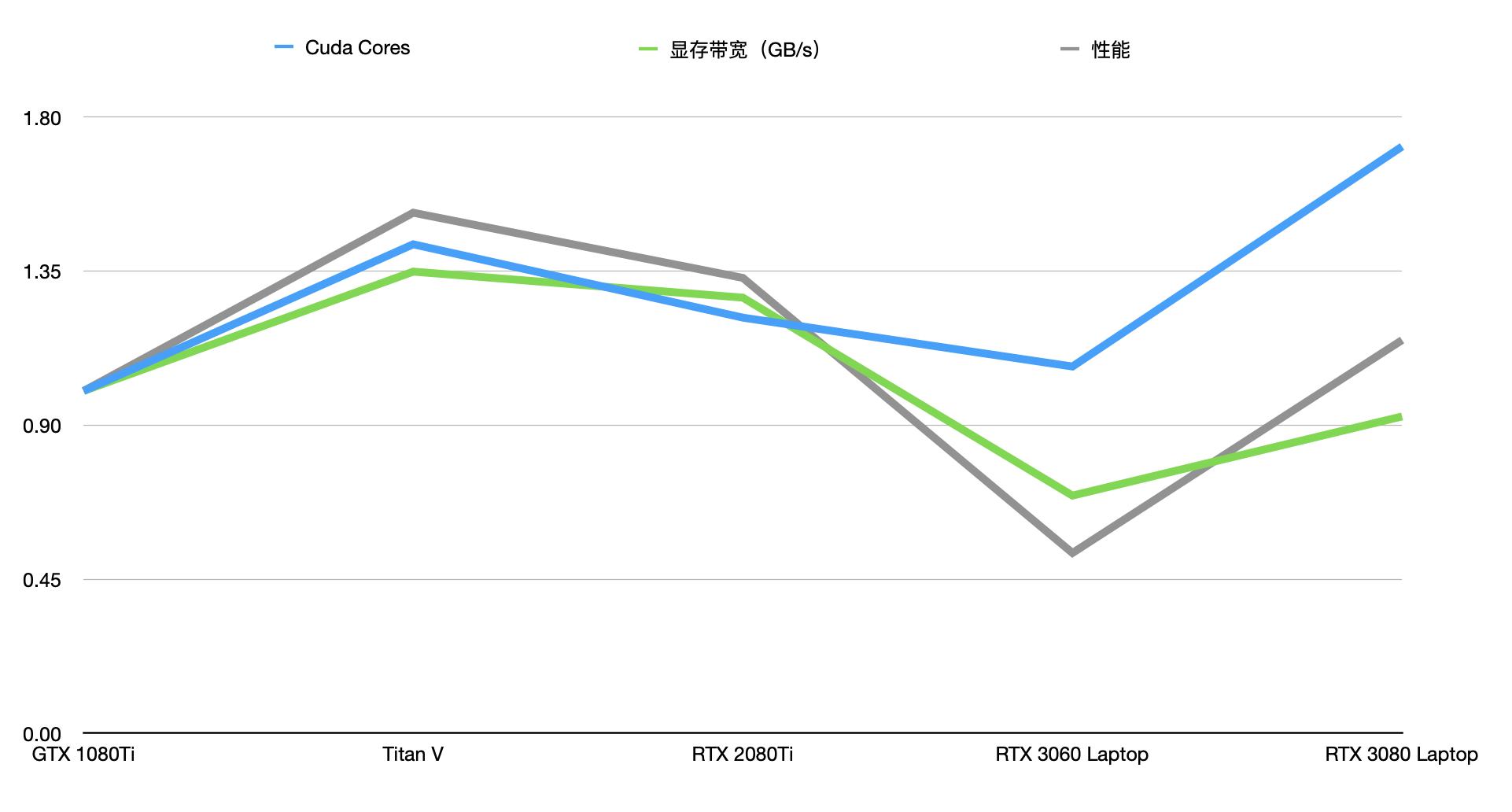
You can see clearly that the performance of the training model is closely related to the memory bandwidth and the number of CUDA.
Notice the memory bandwidth are directly related with performance, the number of Cuda is not necessarily. Because except for GTX 1080 Ti, others have Tensor Cores which designed to calculate tensors. Nowadays, the performance of Tensor Core is much higher and effective, but in design, the number of Tensor Cores is proportional to Cuda Cores.
Of course, it’s better to know the floating point performance of GPU, which is more direct. I try to guess GPU because floating point performance on consumer GPUs is not that easy to find.